





В прошлой статье мы разбирали, как классическое распознавание (OCR) помогает переводить документы в текст и автоматизировать обработку типовых документов. Для многих задач этого действительно хватает, но есть ряд ограничений. OCR извлекает текст, но не понимает его смысл. Поэтому компании переходят к интеллектуальной обработке документов, когда надо анализировать содержание, структуру и связи между данными.
В этой статье разберем, где заканчивается роль OCR, в какой момент подключаются LLM распознавание и какой бизнес-эффект дает их совместная работа в процессах с большим объемом документов.
В этой статье разберем, где заканчивается роль OCR, в какой момент подключаются LLM распознавание и какой бизнес-эффект дает их совместная работа в процессах с большим объемом документов.
Почему обычного OCR уже недостаточно
OCR хорошо работает, когда документы однотипные: например, счета или накладные приходят в одном формате, с понятной структурой и качественными сканами. Но в реальных процессах документы постоянно отличаются: меняются шаблоны, структура, формулировки и расположение полей.
Например, появляется новый поставщик с другим шаблоном коммерческого предложения. Человек быстро понимает, где находятся нужные условия и данные, потому что воспринимает документ целиком и понимает контекст.
OCR так не работает. Он опирается на заранее заданные правила, шаблоны и расположение элементов. Когда структура документа меняется, система начинает ошибаться: некорректно извлекает поля или не находит нужные данные вовсе. Сотрудникам приходится перепроверять извлечённые данные, исправлять ошибки и только потом загружать информацию в ERP или учетные системы.
Проблема особенно заметна на больших объёмах. Например, если компания обрабатывает 10 000 документов в месяц, то даже при точности OCR на уровне 85–90% около 1 000–1 500 документов всё равно потребуют ручного вмешательства.
В итоге с ростом документооборота растёт не только автоматизация, но и объём рутинной работы. Именно поэтому к классическому OCR начинают добавлять LLM-модели. Они позволяют не только считывать текст, но и интерпретировать структуру документа: сопоставлять поля, учитывать контекст и работать с разными форматами без постоянной перенастройки шаблонов.
Например, появляется новый поставщик с другим шаблоном коммерческого предложения. Человек быстро понимает, где находятся нужные условия и данные, потому что воспринимает документ целиком и понимает контекст.
OCR так не работает. Он опирается на заранее заданные правила, шаблоны и расположение элементов. Когда структура документа меняется, система начинает ошибаться: некорректно извлекает поля или не находит нужные данные вовсе. Сотрудникам приходится перепроверять извлечённые данные, исправлять ошибки и только потом загружать информацию в ERP или учетные системы.
Проблема особенно заметна на больших объёмах. Например, если компания обрабатывает 10 000 документов в месяц, то даже при точности OCR на уровне 85–90% около 1 000–1 500 документов всё равно потребуют ручного вмешательства.
В итоге с ростом документооборота растёт не только автоматизация, но и объём рутинной работы. Именно поэтому к классическому OCR начинают добавлять LLM-модели. Они позволяют не только считывать текст, но и интерпретировать структуру документа: сопоставлять поля, учитывать контекст и работать с разными форматами без постоянной перенастройки шаблонов.
Как LLM понимают документы
В основе LLM решений лежит работа с контекстом. Языковая модель анализирует не отдельные строки, а связи между ними: где заголовок и где значение, какие поля относятся друг к другу, как устроена структура документа и что в нём является бизнес-значимым.
Это особенно важно в документах, где один и тот же смысл может быть описан по-разному. Например, в договорах классический поиск ориентируется на отдельные слова вроде «штраф» или «ответственность» и может легко пропустить важные условия, если они сформулированы иначе.
LLM анализирует положение в целом: кто несет ответственность, в каких случаях возникает штраф, есть ли отклонения от стандартных условий и как это влияет на обязательства сторон и дальнейшие действия компании.
Это особенно важно в документах, где один и тот же смысл может быть описан по-разному. Например, в договорах классический поиск ориентируется на отдельные слова вроде «штраф» или «ответственность» и может легко пропустить важные условия, если они сформулированы иначе.
LLM анализирует положение в целом: кто несет ответственность, в каких случаях возникает штраф, есть ли отклонения от стандартных условий и как это влияет на обязательства сторон и дальнейшие действия компании.
OCR и LLM: интеллектуальная обработка документов
На практике OCR и LLM не конкурируют — они работают вместе и в связке формируют основу интеллектуальной обработки документов (IDP).
Из таблицы видно: OCR отвечает за извлечение текста, а LLM — за понимание и интерпретацию
Интеллектуальная обработка документов (IDP, Intelligent Document Processing) — это подход, при котором система не просто извлекает текст из документов, а понимает его содержание и превращает в данные, пригодные для бизнес-использования.
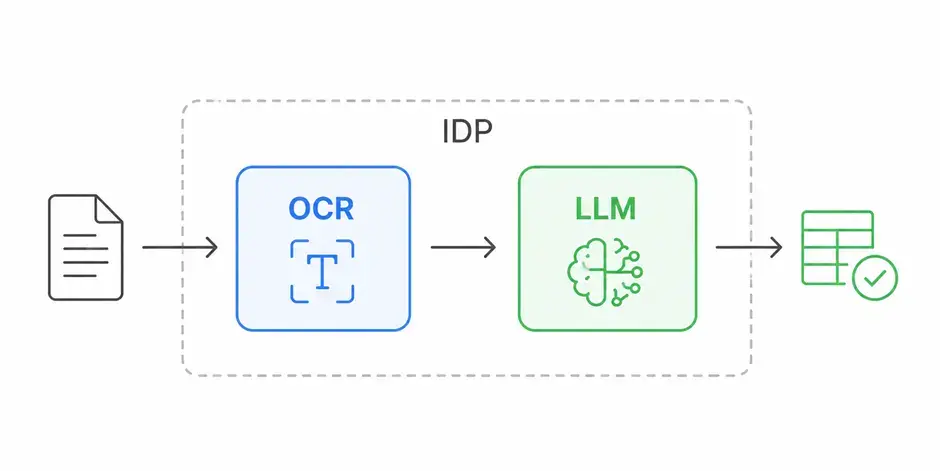
Современные AI-системы обработки документов обычно включают несколько уровней.
Какие задачи решаются с помощью интеллектуальной обработки документов (OCR + LLM)
Извлечение данных из сложных документов
IDP используется для автоматического извлечения ключевых данных из разнородных документов: счета, акты, УПД, договоры, анкеты, тендерные заявки.
Как работает:
Результат:
Как работает:
- OCR извлекает весь текст и структуру (таблицы, поля, блоки)
- LLM определяет, какие элементы являются значимыми и как они связаны
- IDP приводит данные к единому структурированному виду
Результат:
- структурированные данные вместо «сырого» текста
- автоматическое заполнение систем (ERP/CRM)
- снижение ручной обработки до 40–70%
Автоматическая классификация документов
IDP определяет тип документа и запускает нужный бизнес-процесс.
Как работает:
Результат:
Как работает:
- OCR извлекает текстовые маркеры (заголовки, реквизиты)
- LLM определяет смысловой тип документа
- IDP маршрутизирует документ в нужный процесс с интеграцией в ERP
Результат:
- автоматическая сортировка входящего потока
- ускорение документооборота
- снижение ошибок ручной классификации
Анализ договоров и поиск рисков
IDP помогает выявлять риски и отклонения в договорах.
Как работает:
Результат:
Как работает:
- OCR извлекает текст договора и приложений
- LLM анализирует условия и сравнивает с шаблонами
- IDP формирует список рисков и отклонений
Результат:
- выявление нетиповых условий и штрафов
- контроль обязательных пунктов
- ускорение первичного анализа в разы
Краткое содержание документов
IDP формирует краткое содержание длинных документов.
Как работает:
Результат:
Как работает:
- OCR извлекает полный текст
- LLM выделяет ключевые смысловые блоки
- IDP формирует структурированное резюме
Результат:
- быстрый обзор документа без чтения полного текста
- выделение условий, сроков, рисков
- ускорение принятия решений
Проверка соответствия требованиям
IDP контролирует полноту и корректность документов.
Как работает:
Результат:
Как работает:
- OCR извлекает данные из форм и приложений
- LLM проверяет соответствие правилам и регламентам
- IDP формирует отчёт о несоответствиях
Результат:
- выявление ошибок и противоречий
- контроль обязательных полей и комплектности
- снижение операционных рисков
Обработка входящих обращений (почта, заявки, письма)
IDP используется для автоматической обработки неструктурированных входящих сообщений.
Как работает:
Результат:
Это лишь часть типовых сценариев применения IDP. На практике возможности таких систем значительно шире и зависят от конкретных бизнес-процессов, документов и требований компании.
Как работает:
- OCR извлекает текст из писем, PDF и вложений
- LLM определяет суть обращения и намерение
- IDP классифицирует и запускает процесс обработки
Результат:
- автоматическое распределение обращений по отделам
- ускорение реакции на запросы клиентов и партнеров
- снижение нагрузки на операторов
Это лишь часть типовых сценариев применения IDP. На практике возможности таких систем значительно шире и зависят от конкретных бизнес-процессов, документов и требований компании.
Где применяется интеллектуальная обработка документов (OCR + LLM)
Сегодня искусственный интеллект для анализа документов активно применяется в компаниях с большим объемом документооборота.
Почему компании массово переходят от OCR к AI-обработке документов
Экономические причины. IDP даёт измеримый экономический эффект за счёт сокращения ручной обработки документов.
В среднем один документ требует 5–15 минут работы (ввод данных, проверка, сверка, перенос в систему). При потоке 10 000 – 50 000 документов в месяц это уже 1 700 – 8 300 человеко-часов рутинной нагрузки — эквивалент 10–50 сотрудников. Даже частичная автоматизация (30–50%) даёт ощутимый эффект: меньше затрат на операционные команды и возможность обрабатывать растущий объём документов без расширения штата.
Операционные причины. LLM ускоряют обработку входящих документов, что в итоге сокращает время прохождения ключевых этапов бизнес-процессов — согласования, закупок, бухгалтерских операций, обслуживания клиентов и внутреннего документооборота.
Качество данных. При ручной обработке документов неизбежны ошибки: пропуски, дубли, некорректный ввод и несоответствия между системами. IDP решает это за счёт стандартизации данных, а LLM дополнительно помогает выявлять логические несоответствия и отклонения. Итог — более чистые и структурированные данные для дальнейших процессов и аналитики.
В среднем один документ требует 5–15 минут работы (ввод данных, проверка, сверка, перенос в систему). При потоке 10 000 – 50 000 документов в месяц это уже 1 700 – 8 300 человеко-часов рутинной нагрузки — эквивалент 10–50 сотрудников. Даже частичная автоматизация (30–50%) даёт ощутимый эффект: меньше затрат на операционные команды и возможность обрабатывать растущий объём документов без расширения штата.
Операционные причины. LLM ускоряют обработку входящих документов, что в итоге сокращает время прохождения ключевых этапов бизнес-процессов — согласования, закупок, бухгалтерских операций, обслуживания клиентов и внутреннего документооборота.
Качество данных. При ручной обработке документов неизбежны ошибки: пропуски, дубли, некорректный ввод и несоответствия между системами. IDP решает это за счёт стандартизации данных, а LLM дополнительно помогает выявлять логические несоответствия и отклонения. Итог — более чистые и структурированные данные для дальнейших процессов и аналитики.
Какие ограничения остаются у LLM
Несмотря на быстрый рост технологий, полностью автономная обработка документов пока остается редкостью. У LLM есть ограничения, которые необходимо учитывать при внедрении.
- Ошибки интерпретации. LLM может неверно трактовать контекст, путать поля или пропускать отдельные детали документа. Поэтому в критичных процессах результат дополнительно проверяется через бизнес-правила, корпоративные справочники и контроль обязательных полей, сумм и реквизитов.
- Качество исходных документов. Результат напрямую зависит от качества входных данных. При работе с плохо отсканированными файлами, рукописными полями, поврежденными PDF или сложными таблицами точность обработки снижается.
- Безопасность и закрытый контур. Во многих компаниях документы содержат чувствительные данные, которые нельзя передавать во внешние облачные сервисы. Это создаёт ограничения на использование публичных LLM-моделей и требует развёртывания решений во внутреннем контуре компании с отдельными требованиями к хранению, доступу и обработке данных. Особенно критично это для банков, промышленности, медицины и государственного сектора.
- Бизнес-логика и интеграция. LLM не заменяет корпоративные процессы сама по себе. Чтобы система работала стабильно, её нужно встраивать в существующую инфраструктуру: ERP, CRM, маршруты согласования, справочники и внутренние правила компании. Поэтому эффективность IDP зависит не только от качества модели, но и от того, насколько правильно решение встроено в бизнес-процессы.
Будущее интеллектуальной обработки документов
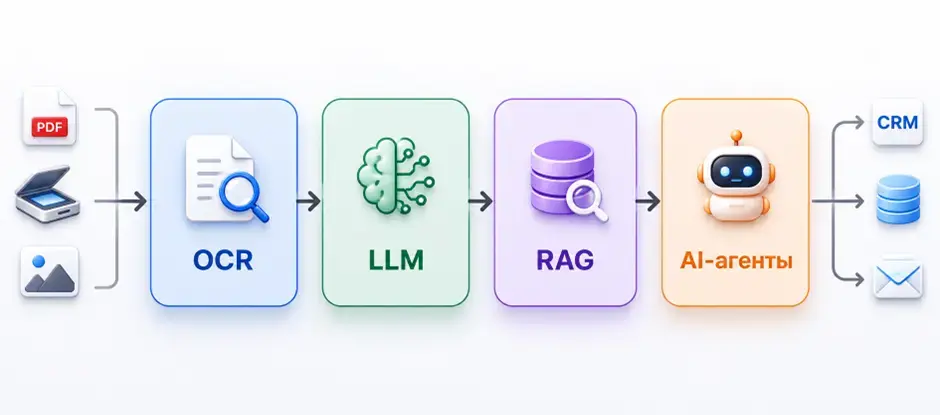
Следующий этап развития обработки документов — объединение OCR, LLM, RAG и AI-агентов в единую систему. В такой архитектуре:
- OCR отвечает за извлечение данных из PDF, сканов и изображений
- LLM — за понимание содержания и принятие решений
- RAG — за поиск и использование корпоративных знаний и документов
- AI-агенты — за выполнение действий в бизнес-системах и автоматизацию процессов
В одном из проектов NordClan была создана система интеллектуального поиска по корпоративным документам на базе OCR, LLM и RAG. У клиента был огромный архив сканированных документов — договоров, накладных, спецификаций и сопутствующей операционной документации.
Мы разработали ИИ-систему поиска по документам: она работает с документами разного качества, извлекает из них текст и позволяет выполнять контекстный поиск по смыслу вопроса. Пользователь получает готовый человекопонятный ответ на запрос любой сложности и ссылки на конкретные документы, на которых этот ответ основан.
Мы разработали ИИ-систему поиска по документам: она работает с документами разного качества, извлекает из них текст и позволяет выполнять контекстный поиск по смыслу вопроса. Пользователь получает готовый человекопонятный ответ на запрос любой сложности и ссылки на конкретные документы, на которых этот ответ основан.
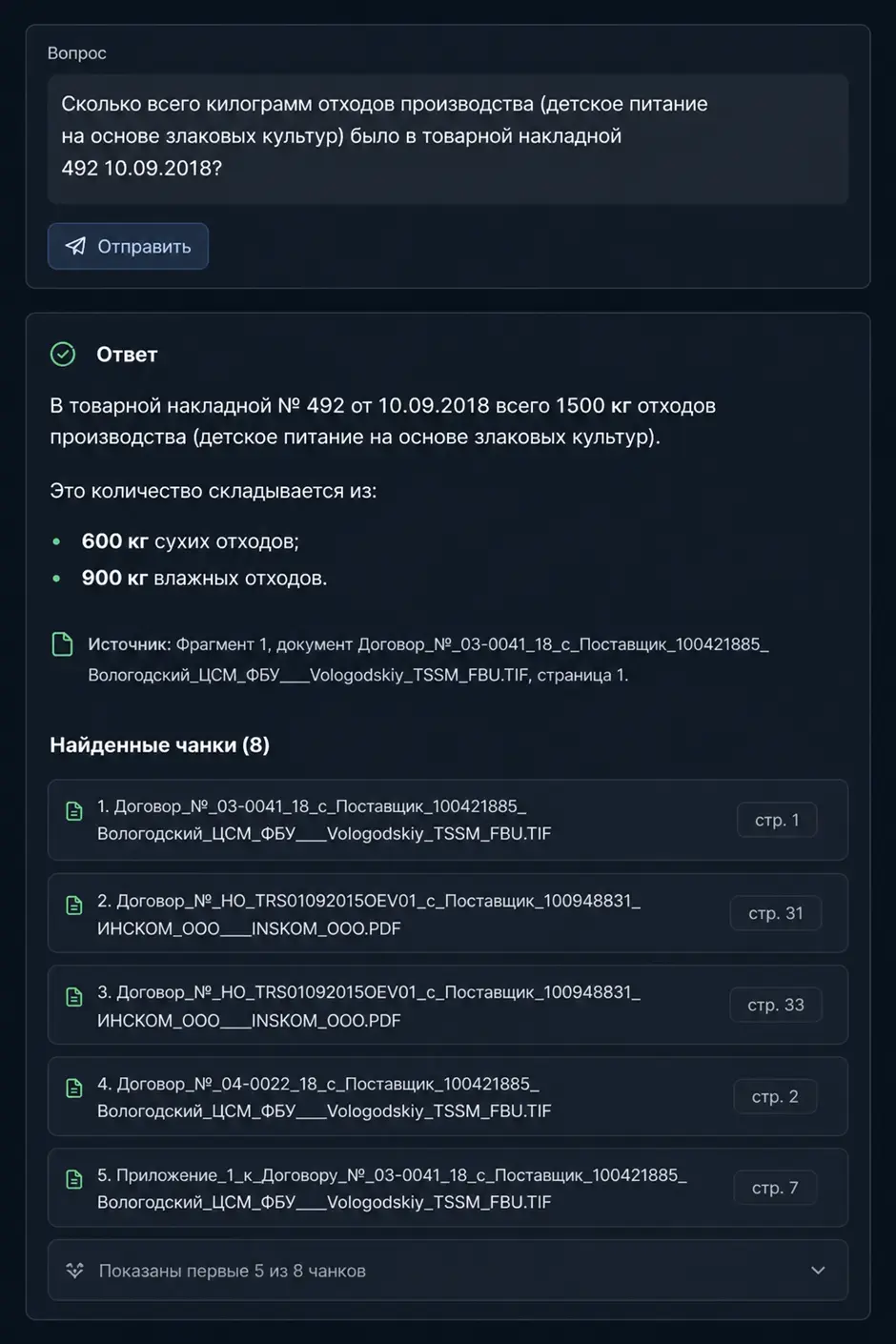
В результате поиск информации занимает секунды вместо минут. Подробности в кейсе.
Параллельно в ближайшие годы будет активно развиваться работа с мультимодальными моделями. Такие системы смогут анализировать не только текст, но и таблицы, схемы, графики, изображения, сложные PDF-документы как единый источник данных и контекста.
Параллельно в ближайшие годы будет активно развиваться работа с мультимодальными моделями. Такие системы смогут анализировать не только текст, но и таблицы, схемы, графики, изображения, сложные PDF-документы как единый источник данных и контекста.
Интеллектуальная обработка документов — это не просто улучшенный OCR, а переход к работе с данными на уровне смысла и бизнес-логики.
OCR отвечает за распознавание текста, а LLM добавляют понимание, проверку и интерпретацию. Вместе они превращают документ из набора слов в источник структурированных данных, которые можно сразу использовать в бизнес-системах.
Но главное изменение не в скорости, а в подходе — документ становятся триггером для дальнейших бизнес-процессов без участия человека, запуская согласования, обновление данных в системах и выполнение операций сразу после поступления документа.
В следующей статье разберём, как OCR, LLM, RAG и AI-агенты объединяются в единую систему: как устроена такая архитектура, как она работает в реальных проектах и какие бизнес-эффекты даёт на практике.
OCR отвечает за распознавание текста, а LLM добавляют понимание, проверку и интерпретацию. Вместе они превращают документ из набора слов в источник структурированных данных, которые можно сразу использовать в бизнес-системах.
Но главное изменение не в скорости, а в подходе — документ становятся триггером для дальнейших бизнес-процессов без участия человека, запуская согласования, обновление данных в системах и выполнение операций сразу после поступления документа.
В следующей статье разберём, как OCR, LLM, RAG и AI-агенты объединяются в единую систему: как устроена такая архитектура, как она работает в реальных проектах и какие бизнес-эффекты даёт на практике.



