





ИИ-поиск по сканированным документам: кейс внедрения RAG + OCR
Разработана ИИ-система поиска по документам для быстрого извлечения информации из большого архива сканированных файлов. Решение сочетает распознавание текста OCR, интеллектуальную обработку содержания документов и контекстный анализ пользовательских запросов. Система умеет работать с документами разного качества, извлекает из них текст и позволяет выполнять контекстный поиск ИИ не по названию файла, а по смыслу вопроса.
Пользователь получает готовый ответ на запрос любой сложности и ссылки на конкретные документы, на которых этот ответ основан.
Пользователь получает готовый ответ на запрос любой сложности и ссылки на конкретные документы, на которых этот ответ основан.
О клиенте
Транснациональная корпорация, производитель продуктов питания и напитков с многолетней историей работы на российском рынке.
Проблема и задачи клиента
У клиента за годы работы накопился большой архив сканированных документов — договоров, накладных, спецификаций и сопутствующей операционной документации. По факту это десятки лет работы компании, разложенные по тысячам отдельных файлов.
При этом документы сильно отличаются по качеству. Есть нормально отсканированные файлы, а есть документы с перекосами, шумом и плохо читаемым текстом. Часть архива — это старые файлы начала 2000-х, которые сохранялись в разных форматах и с разной структурой метаданных.
Из-за этого заранее невозможно понять, где именно находится нужная информация. Даже на простой вопрос приходится тратить много времени на ручной поиск: например, чтобы понять, сколько раз за несколько лет заключались договоры с одним и тем же контрагентом и на каких условиях это происходило, нужно поднимать сразу несколько договоров за разные годы и сверять данные между ними.
Такая работа занимает значительное время и сильно зависит от опыта сотрудника и того, насколько хорошо он ориентируется в архиве. При этом часть запросов приходит от надзорных органов и требует быстрого и точного ответа в строго ограниченные сроки. Дополнительно сохраняется риск человеческой ошибки — при большом объёме разрозненных документов сложно гарантировать, что при ручной проверке ничего не будет упущено.
При этом документы сильно отличаются по качеству. Есть нормально отсканированные файлы, а есть документы с перекосами, шумом и плохо читаемым текстом. Часть архива — это старые файлы начала 2000-х, которые сохранялись в разных форматах и с разной структурой метаданных.
Из-за этого заранее невозможно понять, где именно находится нужная информация. Даже на простой вопрос приходится тратить много времени на ручной поиск: например, чтобы понять, сколько раз за несколько лет заключались договоры с одним и тем же контрагентом и на каких условиях это происходило, нужно поднимать сразу несколько договоров за разные годы и сверять данные между ними.
Такая работа занимает значительное время и сильно зависит от опыта сотрудника и того, насколько хорошо он ориентируется в архиве. При этом часть запросов приходит от надзорных органов и требует быстрого и точного ответа в строго ограниченные сроки. Дополнительно сохраняется риск человеческой ошибки — при большом объёме разрозненных документов сложно гарантировать, что при ручной проверке ничего не будет упущено.
Задача
Клиенту требовалась система, которая позволит быстро находить информацию в архиве сканированных документов и выполнять ИИ поиск по документам через анализ содержания, а не через просмотр файлов.
Важно было, чтобы решение:
Важно было, чтобы решение:
- работало с разными по качеству сканами, включая старые и искажённые документы;
- преобразовывало документы в читаемый структурированный текст;
- объединяло информацию из нескольких документов в один ответ;
- показывало, из каких именно документов получен результат.
Решение
Мы реализовали MVP контекстной системы поиска по документам на базе связки OCR + RAG. По сути это AI поиск по документам, в котором объединены технология распознавания текста OCR, векторный поиск и большая языковая модель.
Как работает
- Распознавание документов. Сканированные файлы проходят через OCR сервис распознавания текста, который обрабатывает в том числе сложные случаи: повороты страниц, низкое качество сканов, старые форматы хранения. Используется оптическое распознавание символов и дополнительная мультимодальная модель для повышения качества извлечения данных.
- Преобразование в текстовую структуру. После этого документы разбиваются на смысловые фрагменты, пригодные для дальнейшего анализа.
- Контекстный поиск. На основе векторной базы знаний и LLM реализован контекстный поиск RAG: система находит релевантные фрагменты сразу в нескольких документах, сопоставляет информацию между ними и формирует единый ответ пользователю. Фактически это контекстный ИИ-поиск, в котором запрос анализируется по смыслу, а не по точному совпадению слов.
- Проверяемость результата. Каждый ответ сопровождается ссылками на исходные документы и конкретные фрагменты текста.
Для сотрудника работа с системой выглядит максимально просто и привычно: он формулирует вопрос естественным языком, как в обычной рабочей задаче.
Например, можно запросить: по каким договорам с конкретным контрагентом в разные годы менялись условия поставок, какие объёмы фактически проходили по этим контрактам и какие дополнительные соглашения на это влияли. В ответ система в естественной форме собирает итоговый вывод, показывает взаимосвязь между найденными документами и даёт ссылки на все использованные источники. Таким образом реализуется полноценный контекстный поиск по архиву без просмотра тысяч файлов.
Например, можно запросить: по каким договорам с конкретным контрагентом в разные годы менялись условия поставок, какие объёмы фактически проходили по этим контрактам и какие дополнительные соглашения на это влияли. В ответ система в естественной форме собирает итоговый вывод, показывает взаимосвязь между найденными документами и даёт ссылки на все использованные источники. Таким образом реализуется полноценный контекстный поиск по архиву без просмотра тысяч файлов.
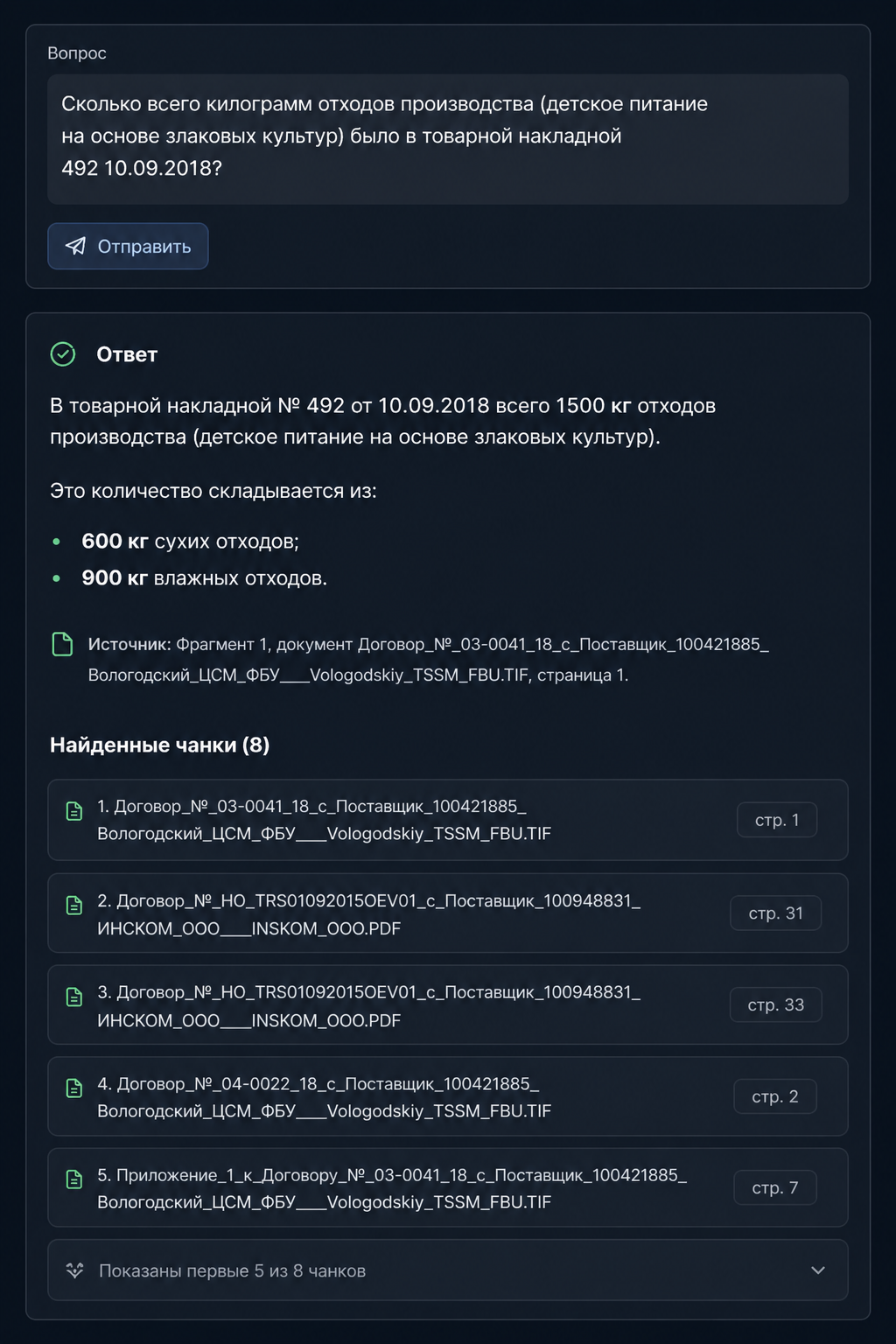
Результат
По результатам работы MVP подтверждён ключевой бизнес-эффект:
MVP подтвердил, что внедрение RAG в задачи корпоративного документооборота позволяет существенно ускорить работу с архивами и снижает зависимость от ручного поиска. Решение показало устойчивость на реальных данных и возможность дальнейшего масштабирования на весь массив документов клиента.
Разрабатываем ИИ-решения на базе OCR, RAG, LLM и компьютерного зрения для поиска информации, анализа документов и автоматизации сложных операционных задач.
- сокращение времени поиска информации с нескольких часов до нескольких минут (в среднем в 10–30 раз быстрее)
- снижение нагрузки на сотрудников, ранее задействованных в этих задачах до ~60–80%
- высокая точность ответов на типовых запросах на уровне ~90%+ с привязкой к источникам
- возможность обработки запросов по десяткам тысяч документов без роста трудозатрат
MVP подтвердил, что внедрение RAG в задачи корпоративного документооборота позволяет существенно ускорить работу с архивами и снижает зависимость от ручного поиска. Решение показало устойчивость на реальных данных и возможность дальнейшего масштабирования на весь массив документов клиента.
Разрабатываем ИИ-решения на базе OCR, RAG, LLM и компьютерного зрения для поиска информации, анализа документов и автоматизации сложных операционных задач.