





ML-сервис для автоматической классификации товарных данных
Создали ML-сервис, который автоматически систематизирует информацию о товарах из неструктурированных Excel- файлов: выделяет бренды, линейки, тип продукции и другие ключевые параметры. За несколько минут система может обработать до 40–50 тысяч товарных позиций и формирует готовую таблицу, которую можно сразу использовать для аналитики и отчетности.

О клиенте
Крупный дистрибьютор косметической продукции. Компания работает с большим количеством брендов и поставщиков и регулярно получает данные о товарах в виде Excel-файлов из разных источников: от поставщиков, складов и логистических партнеров.
Проблема и задачи клиента
Данные о товарах поступали в виде таблиц с длинными строками описаний. Внутри одной строки могли содержаться разные характеристики товара:
- бренд
- линейка продукции
- тип товара
- упаковка
- дополнительные атрибуты
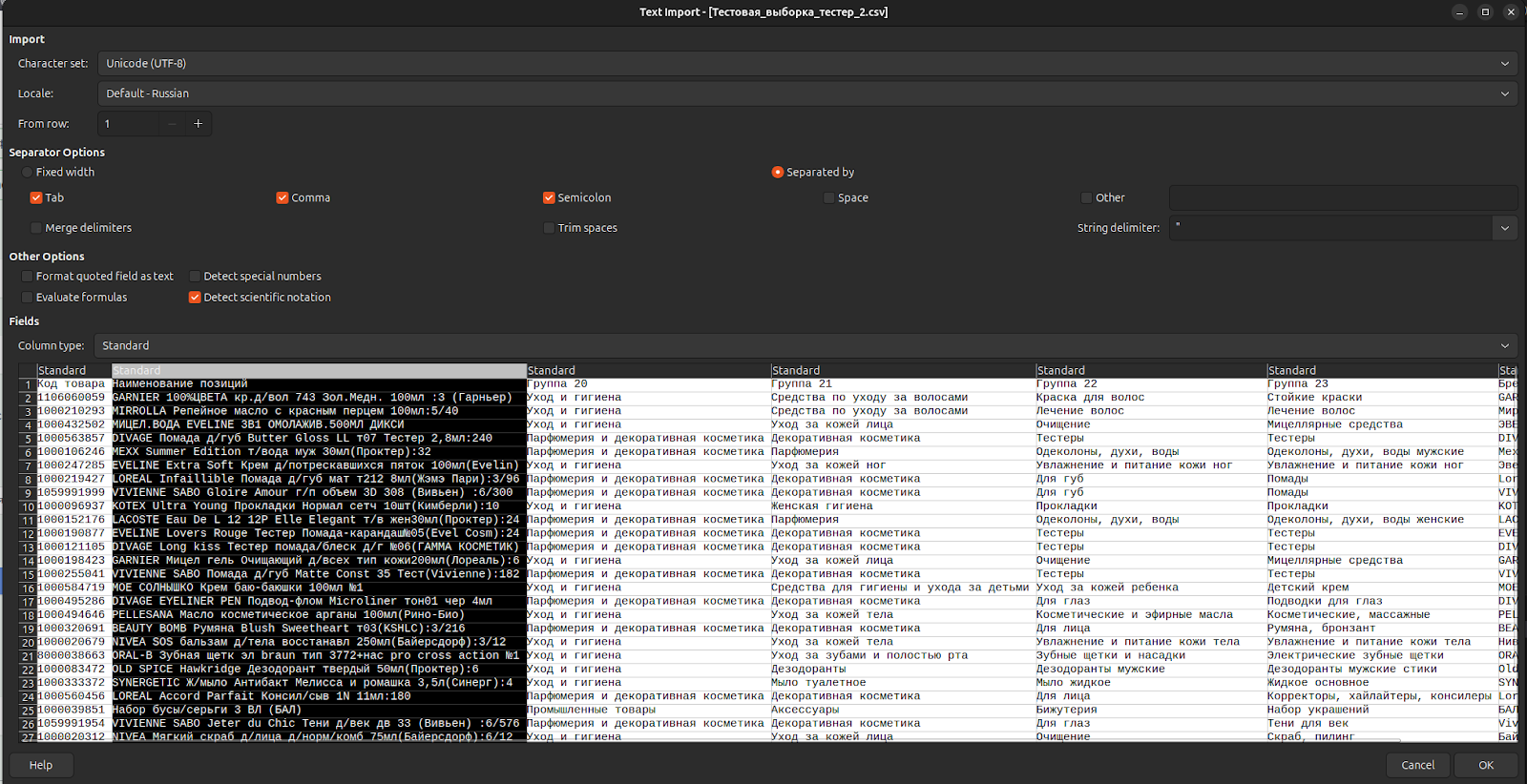
Чтобы использовать эти данные, сотрудникам приходилось вручную разбирать строки и переносить информацию в другой файл, раскладывая её по отдельным колонкам.
Клиент рассматривал вариант использования нейросетей, однако для такой инфраструктуры требовались значительные ресурсы. Это делало решение слишком дорогим для задачи такого типа.
- Объем данных составлял 40–50 тысяч строк каждые несколько недель.
- Ручная обработка занимала много времени, риск ошибок.
Клиент рассматривал вариант использования нейросетей, однако для такой инфраструктуры требовались значительные ресурсы. Это делало решение слишком дорогим для задачи такого типа.
Решение
Мы разработали сервис автоматической классификации товарных данных на базе классических ML-моделей. Система анализирует строку с описанием товара, автоматически выделяет нужные атрибуты: бренд, линейку, тип продукции и другие параметры. Затем переносит нужные данные в новый файл.
Как работает:
- Менеджер загружает новый Excel-файл с поставок.
- Система автоматически разбирает строки по атрибутам.
- Формируется готовый Excel-файл с выделенными атрибутами, который можно сразу использовать для аналитики, отчетности и принятия решений.
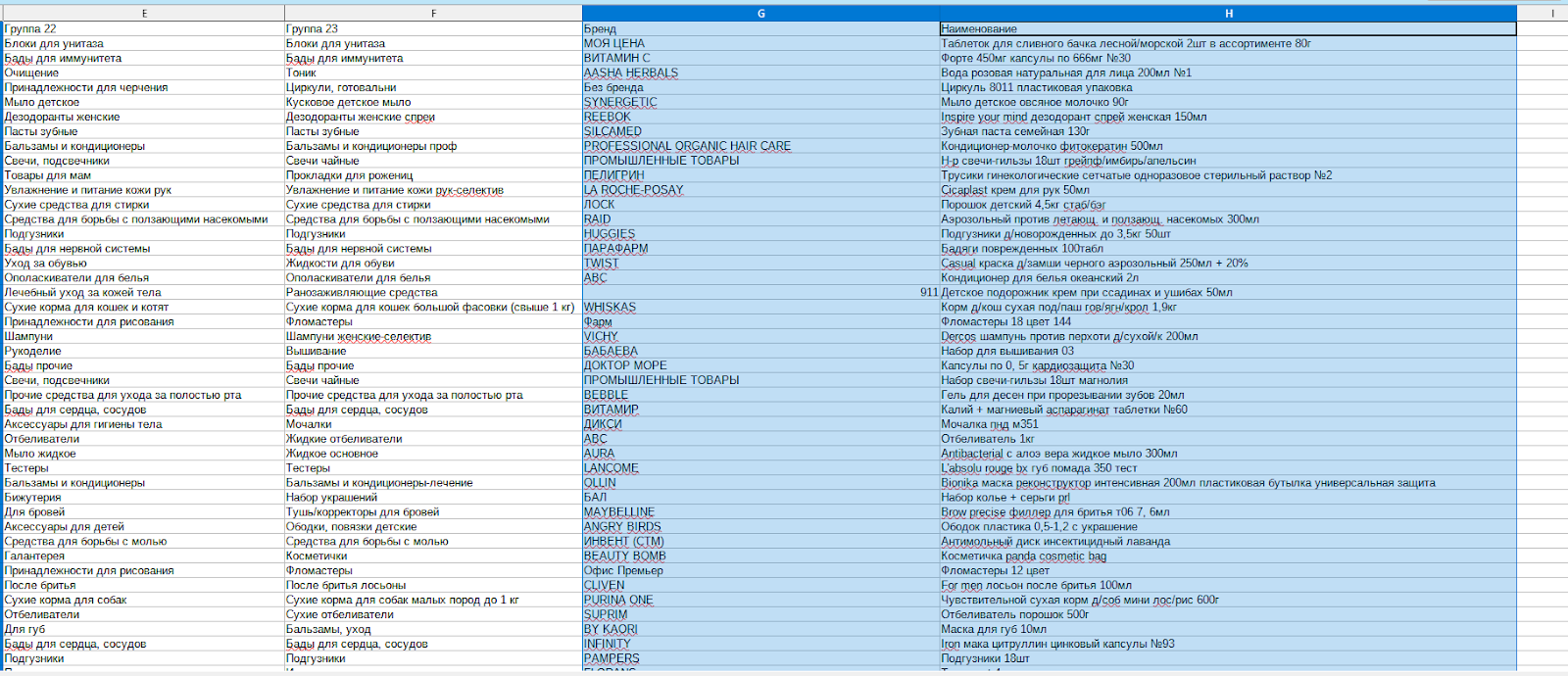
Результат
Обработка 40–50 тысяч товарных позиций выполняется за минуты вместо нескольких часов.