





OCR (Optical Character Recognition) — это технология оптического распознавания символов, которая позволяет превращать изображение текста в цифровые данные.
Если упростить, OCR — это способ «прочитать» картинку: скан, фотографию или PDF и получить из неё редактируемый текст, с которым уже можно работать в системах, базах данных и документах. Именно так работает распознавание текста OCR: система анализирует изображение и выделяет в нём символы, слова и структуру текста.
Сегодня это уже не программа для сканеров, а полноценные платформы для обработки документов. OCR технологии используются там, где нужно быстро переводить бумажный или визуальный контент в данные — без ручного ввода.
Если упростить, OCR — это способ «прочитать» картинку: скан, фотографию или PDF и получить из неё редактируемый текст, с которым уже можно работать в системах, базах данных и документах. Именно так работает распознавание текста OCR: система анализирует изображение и выделяет в нём символы, слова и структуру текста.
Сегодня это уже не программа для сканеров, а полноценные платформы для обработки документов. OCR технологии используются там, где нужно быстро переводить бумажный или визуальный контент в данные — без ручного ввода.
Что такое OCR и почему он стал базовой технологией
Большая часть документов в компаниях по-прежнему приходит в виде изображений: сканы, PDF, фотографии, заполненные вручную формы. С ними нельзя работать напрямую — данные приходится переносить вручную.
По оценкам отраслевых исследований, ручной ввод занимает в среднем от 2 до 5 минут на один простой документ, а уровень ошибок может доходить 3%. При потоках в тысячи и десятки тысяч документов в день это превращается в значительную операционную нагрузку: сотни человеко-часов в месяц только на ввод и проверку данных.
OCR убирает этот этап. Информация из документа сразу попадает в систему, а человек работает только с проверкой исключений и нестандартных случаев.
Именно поэтому технология стала базовой: в любом процессе, где есть поток входящих документов, работа с данными вручную становится ограничением по скорости, стоимости и масштабированию.
По оценкам отраслевых исследований, ручной ввод занимает в среднем от 2 до 5 минут на один простой документ, а уровень ошибок может доходить 3%. При потоках в тысячи и десятки тысяч документов в день это превращается в значительную операционную нагрузку: сотни человеко-часов в месяц только на ввод и проверку данных.
OCR убирает этот этап. Информация из документа сразу попадает в систему, а человек работает только с проверкой исключений и нестандартных случаев.
Именно поэтому технология стала базовой: в любом процессе, где есть поток входящих документов, работа с данными вручную становится ограничением по скорости, стоимости и масштабированию.
Для чего используется OCR в реальных процессах
Во многих компаниях работа с документами выглядит одинаково: они приходят каждый день, в разном виде и с разным качеством сканов, но почти всегда задача одна — быстро получить из них нужные данные и передать в систему.
OCR используют как раз в таких случаях. Когда документов много и они повторяются по структуре, нет смысла разбирать каждый вручную — важнее быстро извлечь данные и передать их дальше в учетные системы.
В типовых сценариях он помогает:
OCR используют как раз в таких случаях. Когда документов много и они повторяются по структуре, нет смысла разбирать каждый вручную — важнее быстро извлечь данные и передать их дальше в учетные системы.
В типовых сценариях он помогает:
- обрабатывать счета и акты;
- извлекать данные из паспортов и анкет;
- оцифровывать архивы;
- распознавать чеки;
- ускорять документооборот;
- делать поиск по документам.
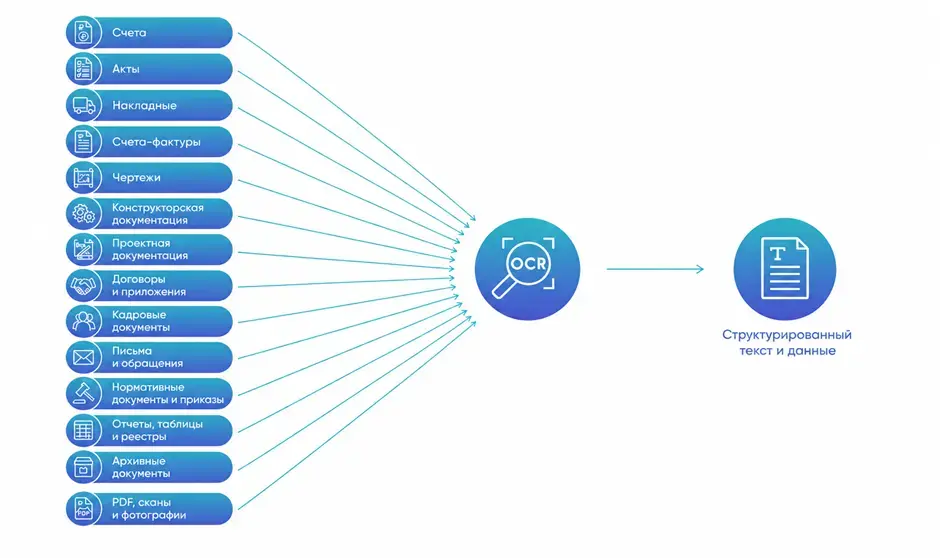
Какие бывают OCR технологии
OCR — это не одна технология, а набор подходов, которые решают разные задачи в зависимости от типа документов и качества данных. На практике системы распознавания текста развивались постепенно: от простого чтения печатного текста до решений, которые умеют работать с разными форматами документов и их структурой.
Классический OCR. Базовый вариант, который используется для печатного текста. Он хорошо работает со стандартными сканами, PDF-документами и файлами с понятной структурой. Чаще всего применяется там, где текст напечатан, качество изображения нормальное, а структура документа предсказуема.
ICR (Intelligent Character Recognition). Используется для рукописного текста. В таких задачах подключаются алгоритмы, которые учитывают особенности почерка и вариативность написания символов. Чаще всего применяется в заполненных вручную анкетах, заявлениях и формах с рукописными полями.
OMR (Optical Mark Recognition). Технология для распознавания отметок, а не текста. Система фиксирует галочки, выбор вариантов и заполненные поля. Используется в тестах, анкетах и формах голосования.
Распознавание штрихкодов и QR-кодов. Отдельное направление, которое часто используется вместе с OCR. Позволяет быстро идентифицировать документы, товары и объекты в логистике и ритейле.
AI OCR / Intelligent Document Processing. Продвинутый уровень технологий, где система не только распознаёт текст, но и понимает структуру документа: выделяет заголовки, таблицы, отдельные поля и связи между данными. Используется там, где важно работать не с текстом, а с содержанием документа в целом.
Классический OCR. Базовый вариант, который используется для печатного текста. Он хорошо работает со стандартными сканами, PDF-документами и файлами с понятной структурой. Чаще всего применяется там, где текст напечатан, качество изображения нормальное, а структура документа предсказуема.
ICR (Intelligent Character Recognition). Используется для рукописного текста. В таких задачах подключаются алгоритмы, которые учитывают особенности почерка и вариативность написания символов. Чаще всего применяется в заполненных вручную анкетах, заявлениях и формах с рукописными полями.
OMR (Optical Mark Recognition). Технология для распознавания отметок, а не текста. Система фиксирует галочки, выбор вариантов и заполненные поля. Используется в тестах, анкетах и формах голосования.
Распознавание штрихкодов и QR-кодов. Отдельное направление, которое часто используется вместе с OCR. Позволяет быстро идентифицировать документы, товары и объекты в логистике и ритейле.
AI OCR / Intelligent Document Processing. Продвинутый уровень технологий, где система не только распознаёт текст, но и понимает структуру документа: выделяет заголовки, таблицы, отдельные поля и связи между данными. Используется там, где важно работать не с текстом, а с содержанием документа в целом.
Как работает OCR
Если разложить процесс, он всегда начинается одинаково — с входного документа. Это может быть скан, фото или PDF. Дальше система приводит изображение в порядок: выравнивает, убирает шум, корректирует контраст. Это важный этап, потому что качество распознавания напрямую зависит от исходного изображения.
После этого начинается поиск текстовых областей. Система определяет, где находятся строки, слова и отдельные символы. Затем происходит распознавание — именно здесь используются алгоритмы машинного обучения или нейросети, которые сопоставляют визуальные паттерны с символами языка.
Финальный шаг — структурирование результата. Текст превращается в формат, с которым можно работать дальше: DOCX, Excel, JSON или напрямую передаётся в CRM и ERP-системы.
После этого начинается поиск текстовых областей. Система определяет, где находятся строки, слова и отдельные символы. Затем происходит распознавание — именно здесь используются алгоритмы машинного обучения или нейросети, которые сопоставляют визуальные паттерны с символами языка.
Финальный шаг — структурирование результата. Текст превращается в формат, с которым можно работать дальше: DOCX, Excel, JSON или напрямую передаётся в CRM и ERP-системы.
Где применяется OCR
OCR давно перестал быть узкоспециализированной технологией. Сейчас это базовый инструмент цифровых процессов в разных отраслях.
Банки и финансы. В финансовом секторе OCR используют там, где важны скорость обработки документов и точность данных на входе. Это, например, распознавание паспортов, обработка заявок и договоров. Такой подход позволяет быстрее проверять документы и снижает нагрузку на сотрудников, которые раньше вручную заносили данные.
Бухгалтерия. В бухгалтерских процессах OCR помогает убрать ручной ввод данных. Счета и акты автоматически попадают в систему, информация сразу передаётся в ERP, а количество ошибок в реквизитах заметно снижается.
Юридическая сфера. В юридических компаниях и департаментах OCR применяют для работы с договорами, судебными документами и большими массивами текстов. Он помогает быстро переводить бумажные и сканированные материалы в текстовый формат, чтобы упростить поиск по документам, анализ условий и подготовку материалов по делам.
Логистика. Здесь OCR используется для работы с документами на каждом этапе движения груза. Распознаются накладные, применяются штрихкоды и QR-коды, автоматизируется складской учёт и обработка сопроводительных документов.
Ритейл. В рознице технология работает с большим количеством однотипных документов: чеки, ценники, маркировка товаров.
Медицина. В медицине OCR используют для перевода бумажных архивов в электронный формат. Это оцифровка медицинских карт, обработка анализов и работа с рецептами.
Государственный сектор. Здесь ключевая задача — обработка больших массивов документов. OCR применяют для перевода архивов в электронный вид, обработки заявлений и упрощения документооборота.
Банки и финансы. В финансовом секторе OCR используют там, где важны скорость обработки документов и точность данных на входе. Это, например, распознавание паспортов, обработка заявок и договоров. Такой подход позволяет быстрее проверять документы и снижает нагрузку на сотрудников, которые раньше вручную заносили данные.
Бухгалтерия. В бухгалтерских процессах OCR помогает убрать ручной ввод данных. Счета и акты автоматически попадают в систему, информация сразу передаётся в ERP, а количество ошибок в реквизитах заметно снижается.
Юридическая сфера. В юридических компаниях и департаментах OCR применяют для работы с договорами, судебными документами и большими массивами текстов. Он помогает быстро переводить бумажные и сканированные материалы в текстовый формат, чтобы упростить поиск по документам, анализ условий и подготовку материалов по делам.
Логистика. Здесь OCR используется для работы с документами на каждом этапе движения груза. Распознаются накладные, применяются штрихкоды и QR-коды, автоматизируется складской учёт и обработка сопроводительных документов.
Ритейл. В рознице технология работает с большим количеством однотипных документов: чеки, ценники, маркировка товаров.
Медицина. В медицине OCR используют для перевода бумажных архивов в электронный формат. Это оцифровка медицинских карт, обработка анализов и работа с рецептами.
Государственный сектор. Здесь ключевая задача — обработка больших массивов документов. OCR применяют для перевода архивов в электронный вид, обработки заявлений и упрощения документооборота.
Ограничения OCR и где он перестаёт работать
Несмотря на то что OCR технологии сильно продвинулись за последние годы, у них остаются вполне понятные ограничения.
Именно в этих сценариях становится заметно, что одного распознавания недостаточно: документ нужно не только прочитать, но и правильно интерпретировать как набор связанных данных.
- Качество исходных данных. OCR чувствителен к качеству изображений. Если скан размытый, документ сфотографирован под углом или имеет низкое разрешение, точность распознавания падает. В таких случаях система может ошибаться в символах, пропускать части текста или искажать данные. Особенно это заметно в документах, где важны цифры и реквизиты.
- Нестандартные форматы и сложная структура. Сложные таблицы, вложенные блоки, смешанная верстка и нестандартные шаблоны создают трудности для распознавания. OCR хорошо справляется с линейным текстом, но когда информация распределена по документу, система может потерять связи между элементами.
- Рукописный текст. Даже с использованием ICR качество распознавания сильно зависит от того, на каких данных обучалась модель. Разные стили почерка, неаккуратное заполнение или нестабильные формы символов снижают точность. В результате распознавание может быть частично верным, но с ошибками в отдельных символах или словах, что критично для финансовых и юридических данных.
- Понимание контекста документа. OCR извлекает текст, но не всегда понимает его смысловую структуру. Например, в счёте система может корректно распознать все числа, но не различить, где итоговая сумма, где НДС, а где промежуточные значения. То же самое относится к договорам и формам, где важна связь между полями, а не просто наличие текста.
Именно в этих сценариях становится заметно, что одного распознавания недостаточно: документ нужно не только прочитать, но и правильно интерпретировать как набор связанных данных.
Вместо вывода
OCR стал базовой технологией работы с документами — тем самым первым шагом, который переводит изображение в данные. Подробнее о том, как OCR применяется в реальных проектах и какие задачи закрывает, можно посмотреть на странице OCR-решения.
Но важно понимать его границу: он хорошо справляется с извлечением текста, но не всегда с его интерпретацией. И именно на этом этапе начинается следующая логика — когда к OCR добавляются модели, которые умеют работать не только с текстом, но и со смыслом документа.
Но важно понимать его границу: он хорошо справляется с извлечением текста, но не всегда с его интерпретацией. И именно на этом этапе начинается следующая логика — когда к OCR добавляются модели, которые умеют работать не только с текстом, но и со смыслом документа.



